
From playlist k-Nearest Neighbor Algorithm

Hello and welcome to a special extra episode of the freshly named Ken’s Nearest Neighbors podcast! It is pretty obvious, but we have chosen a name! Special thanks to Cillian Raftery for suggesting it! Cillian, if you haven’t gotten my message already, please shoot me an email so I can get
From playlist Ken's Nearest Neighbors Podcast

k-NN 4: which distance function?
[http://bit.ly/k-NN] The nearest-neighbour algorithm is sensitive to the choice of distance function. Euclidean distance (L2) is a common choice, but it may lead to sub-optimal performance. We discuss Minkowski (p-norm) distance functions, which generalise the Euclidean distance, and can a
From playlist Nearest Neighbour Methods

Podcast Update, Feedback, and Future Plans - KNN Ep. 126
In this episode, I give a short update on the podcast, ask for feedback on ways to improve, and talk about the future of KNN and my YouTube channel. Listen to Ken's Nearest Neighbors on all the main podcast platforms! On Apple Podcasts: https://podcasts.apple.com/us/podcast/kens-nearest-
From playlist Ken's Nearest Neighbors Podcast

Hedge Funds, Startups, and Data Science Oh my! (@DataLeap) - KNN EP. 14
In this video I had the pleasure of speaking with Andrew from dataleap. He is data scientist and youtuber who is providing a great resource free industry education. He breaks down complex data science concepts with his own unique brand of comedy sprinkled in. You also get to enjoy some cor
From playlist Ken's Nearest Neighbors Podcast

k nearest neighbor (kNN): how it works
[http://bit.ly/k-NN] The k-nearest neighbor (k-NN) algorithm is based on the intuition that similar instances should have similar class labels (in classification) or similar target values (regression). The algorithm is very simple, but is capable of learning highly-complex non-linear decis
From playlist Nearest Neighbour Methods

Graph-Based Approximate Nearest Neighbors (ANN) and HNSW
In the last decade graph-based indexes have gained massive popularity due to their effectiveness, generality and dynamic nature and are now the backbone of many practical large-scale approximate nearest neighbor search solutions. In this practical workshop led by Yury Malkov, author of HNS
From playlist Talks

Machine Learning Lecture 28 "Ball Trees / Decision Trees" -Cornell CS4780 SP17
Lecture Notes: http://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/lecturenote16.html http://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/lecturenote17.html
From playlist CORNELL CS4780 "Machine Learning for Intelligent Systems"
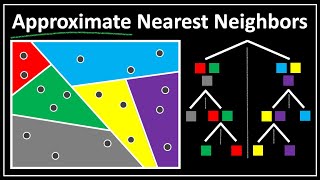
Approximate Nearest Neighbors : Data Science Concepts
Like KNN but a lot faster. Blog post by creator of ANNOY : https://erikbern.com/2015/10/01/nearest-neighbors-and-vector-models-part-2-how-to-search-in-high-dimensional-spaces.html My Patreon : https://www.patreon.com/user?u=49277905
From playlist Data Science Concepts

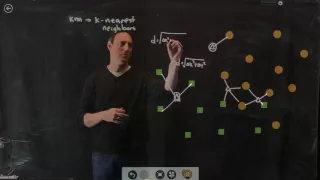
Clustering and Classification: Introduction, Part 3
Data Science for Biologists Clustering and Classification: Introduction Part 3 Course Website: data4bio.com Instructors: Nathan Kutz: faculty.washington.edu/kutz Bing Brunton: faculty.washington.edu/bbrunton Steve Brunton: faculty.washington.edu/sbrunton
From playlist Data Science for Biologists

Do You Have a Data Science Mentor? (@Danny Ma) - KNN EP. 06
In this video, I spoke with Danny Ma about value and mentorship in data science. Danny progressed from humble beginnings in data entry all the way to starting his own data science consulting company. Danny also has a tremendous social reach through linkedin and loves mentoring people inter
From playlist Ken's Nearest Neighbors Podcast

Dense Retrieval ❤ Knowledge Distillation
In this lecture we learn about the (potential) future of search: dense retrieval. We study the setup, specific models, and how to train DR models. Then we look at how knowledge distillation greatly improves the training of DR models and topic aware sampling to get state-of-the-art results.
From playlist Advanced Information Retrieval 2021 - TU Wien

Approximate nearest neighbor search in high dimensions – Piotr Indyk – ICM2018
Mathematical Aspects of Computer Science Invited Lecture 14.7 Approximate nearest neighbor search in high dimensions Piotr Indyk Abstract: The nearest neighbor problem is defined as follows: Given a set P of n points in some metric space (X,𝖣), build a data structure that, given any poin
From playlist Mathematical Aspects of Computer Science
Machine Learning Lecture 27 "Gaussian Processes II / KD-Trees / Ball-Trees" -Cornell CS4780 SP17
Lecture Notes: http://www.cs.cornell.edu/courses/cs4780/2018fa/lectures/lecturenote15.html
From playlist CORNELL CS4780 "Machine Learning for Intelligent Systems"


Data Science Basics: Pipelines
Live Jupyter walk-through of basic machine learning pipelines in Python with the scikit-learn package. I start from a simple predictive machine learning modeling workflow and then repeat it with pipelines. Then I add complexity. This should be enough to get anyone started building data ana
From playlist Data Science Basics in Python