
More Standard Deviation and Variance
Further explanations and examples of standard deviation and variance
From playlist Unit 1: Descriptive Statistics
Data that are collected for statistical analysis can be classified according to their type. It is important to know what data type we are dealing with as this determines the type of statistical test to use.
From playlist Learning medical statistics with python and Jupyter notebooks

Percentiles, Deciles, Quartiles
Understanding percentiles, quartiles, and deciles through definitions and examples
From playlist Unit 1: Descriptive Statistics

(PP 6.1) Multivariate Gaussian - definition
Introduction to the multivariate Gaussian (or multivariate Normal) distribution.
From playlist Probability Theory

Statistics Lecture 5.2: A Study of Probability Distributions, Mean, and Standard Deviation
https://www.patreon.com/ProfessorLeonard Statistics Lecture 5.2: A Study of Probability Distributions, Mean, and Standard Deviation
From playlist Statistics (Full Length Videos)

VARIABLES in Statistical Research (2-1)
A variable is any characteristic that can vary. An organized collection of numbers can be a variable. Qualitative variables indicate an attribute or belongingness to a category. Dichotomous variables are discrete variables that can have two and only two values. Quantitative variables indic
From playlist Forming Variables for Statistics & Statistical Software (WK 2 - QBA 237)
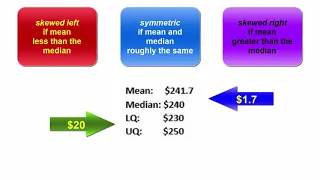
Mean v Median and the implications
Differences between the mean and median suggest the presence of outliers and/or the possible shape of a distribution
From playlist Unit 1: Descriptive Statistics
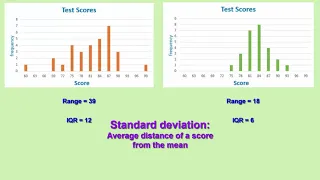
Introduction to standard deviation, IQR [Inter-Quartile Range], and range
From playlist Unit 1: Descriptive Statistics

An Introduction to Classification
Get a Free Trial: https://goo.gl/C2Y9A5 Get Pricing Info: https://goo.gl/kDvGHt Ready to Buy: https://goo.gl/vsIeA5 Develop predictive models for classifying data. For more videos, visit http://www.mathworks.com/products/statistics/examples.html
From playlist Math, Statistics, and Optimization

Overview of logistic regression, a statistical classification technique.
From playlist Machine Learning

Two Statistical Challenges in Classification of Variable Sources by James long
20 March 2017 to 25 March 2017 VENUE: Madhava Lecture Hall, ICTS, Bengaluru This joint program is co-sponsored by ICTS and SAMSI (as part of the SAMSI yearlong program on Astronomy; ASTRO). The primary goal of this program is to further enrich the international collaboration in the area
From playlist Time Series Analysis for Synoptic Surveys and Gravitational Wave Astronomy

Sophie Achard: Statistical comparisons of spatio-temporal networks
CONFERENCE Recording during the thematic meeting : " Machine Learning and Signal Processing on Graphs" the November 7, 2022 at the Centre International de Rencontres Mathématiques (Marseille, France) Filmmaker: Guillaume Hennenfent Find this video and other talks given by worldwide math
From playlist Probability and Statistics
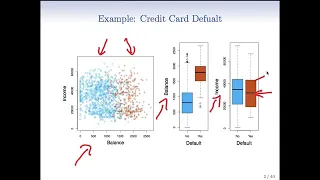
Statistical Learning: 4.1 Introduction to Classification Problems
Statistical Learning, featuring Deep Learning, Survival Analysis and Multiple Testing You are able to take Statistical Learning as an online course on EdX, and you are able to choose a verified path and get a certificate for its completion: https://www.edx.org/course/statistical-learning
From playlist Statistical Learning

WiDS Livermore 2022 | Beginner Workshop Track
On March 7, 2022, LLNL hosted its fifth annual WiDS Livermore event in conjunction with the worldwide Women in Data Science (WiDS) conference. Learn more about WiDS Livermore at https://data-science.llnl.gov/wids. Gale M. Lucas, a research assistant professor at the University of Southern
From playlist WiDS Livermore

Fellow Short Talks: Professor Richard Samworth, Cambridge University
Bio Richard Samworth is Professor of Statistics in the Statistical Laboratory at the University of Cambridge and a Fellow of St John’s College. He received his PhD, also from the University of Cambridge, in 2004, and currently holds an EPSRC Early Career Fellowship. Research His main r
From playlist Short Talks
Statistical Learning: 4.R.3 Nearest Neighbor Classification
Statistical Learning, featuring Deep Learning, Survival Analysis and Multiple Testing You are able to take Statistical Learning as an online course on EdX, and you are able to choose a verified path and get a certificate for its completion: https://www.edx.org/course/statistical-learning
From playlist Statistical Learning
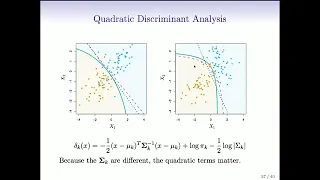
Statistical Learning: 4.9 Quadratic Discriminant Analysis and Naive Bayes
Statistical Learning, featuring Deep Learning, Survival Analysis and Multiple Testing You are able to take Statistical Learning as an online course on EdX, and you are able to choose a verified path and get a certificate for its completion: https://www.edx.org/course/statistical-learning
From playlist Statistical Learning

Machine learning descriptors in chemistry: prediction and experimental validation of UCd3
Dr. Anton Oliynyk delivers an excellent webinar on machine learning for structure predictions as part of our SSMCDAT2020 Hackathon webinar series. Check out prior speakers in the links below: George Karniadakis: https://youtu.be/I2YmQQgcUMg Sergei Kalinin: https://youtu.be/gHvMPoOxmjk
From playlist Materials Informatics

This video explains how to determine mean, median and mode. It also provided examples. http://mathispower4u.yolasite.com/
From playlist Statistics: Describing Data

CSE 519 -- Lecture 17, Fall 2020
From playlist CSE 519 -- Fall 2020