


Business Data Analysis with Excel
Business data presents a challenge for the data analyst. Business data is often aggregated, recorded over time, and tends to exhibit autocorrelation. Additionally, and most problematically, the amount of business data is usually quite limited. These characteristics lead to a situation wher
From playlist Data Analytics Tutorials

A #database #index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. Indexes are used to quickly locate data without having to search every row in a database
From playlist Database

This video explains the fundamental principles of indexing table columns in a database to speed up queries. It illustrates the difference between clustered indexes and non-clustered indexes, which are also known as secondary keys. It explains that the primary key of a table is normally t
From playlist Databases

F-measure is a harmonic mean of recall and precision. Think of it as accuracy, but without the effect of true negatives (which made accuracy meaningless for evaluating search algorithms). F-measure can also be interpreted as the Dice coefficient between the relevant set and the retrieved s
From playlist IR13 Evaluating Search Engines

14 Data Analytics: Indicator Methods
Lecture on the use of indicators for spatial estimation and simulation.
From playlist Data Analytics and Geostatistics

Entanglement & C-theorems (Chandrasekhar lecture III) - part 2
Discussion Meeting: Entanglement from Gravity(URL: http://www.icts.res.in/discussion_meeting/EG2014/) Dates: Wednesday 10 Dec, 2014 - Friday 12 Dec, 2014 Description: In the last few years, quantum entanglement considerations have led to profound insights in the connection with gravity.
From playlist Chandrasekhar Lectures
(IC 1.6) A different notion of "information"
An informal discussion of the distinctions between our everyday usage of the word "information" and the information-theoretic notion of "information". A playlist of these videos is available at: http://www.youtube.com/playlist?list=PLE125425EC837021F Attribution for image of TV static:
From playlist Information theory and Coding
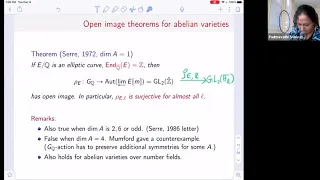
Padma Srinivasan, Computing exceptions primes for Galois representations of abelian surfaces
VaNTAGe Seminar on Dec 8, 2020 License CC-BY-NC-SA
From playlist ICERM/AGNTC workshop updates
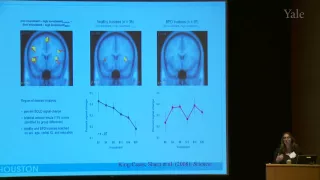
11th Annual Yale NEA-BPD Conference: Mentalization in Borderline Personality Disorder
Mentalization in Borderline Personality Disorder: From Bench to Bedside, Carla Sharp, PhD Dr. Sharp trained as a clinical psychologist (University of Stellenbosch, South Africa) from 1994-1997, after which she completed a Ph.D. in Developmental Psychopathology at Cambridge University, UK,

L16.2 LMS Estimation in the Absence of Observations
MIT RES.6-012 Introduction to Probability, Spring 2018 View the complete course: https://ocw.mit.edu/RES-6-012S18 Instructor: John Tsitsiklis License: Creative Commons BY-NC-SA More information at https://ocw.mit.edu/terms More courses at https://ocw.mit.edu
From playlist MIT RES.6-012 Introduction to Probability, Spring 2018

Statistical Rethinking Fall 2017 - week04 lecture08
Week 04, lecture 08 for Statistical Rethinking: A Bayesian Course with Examples in R and Stan, taught at MPI-EVA in Fall 2017. This lecture covers Chapter 6. Slides are available here: https://speakerdeck.com/rmcelreath Additional information on textbook and R package here: http://xcel
From playlist Statistical Rethinking Fall 2017

QRM 7-2: TS for RM 2 (PACF, ARMA estimation and forecasting)
Welcome to Quantitative Risk Management (QRM). In the second part of Lesson 7, we first introduce the partial autocorrelogram (PACF) and see how we can combine it with the ACF to understand something more about AR, MA and ARMA processes. We then deal with the important problems of estima
From playlist Quantitative Risk Management

Differences between primary data and secondary data in research.
From playlist Experimental Design

Waves, Instabilities and Mixing in Stars by Pascale Garaud
DISCUSSION MEETING WAVES, INSTABILITIES AND MIXING IN ROTATING AND STRATIFIED FLOWS (ONLINE) ORGANIZERS: Thierry Dauxois (CNRS & ENS de Lyon, France), Sylvain Joubaud (ENS de Lyon, France), Manikandan Mathur (IIT Madras, India), Philippe Odier (ENS de Lyon, France) and Anubhab Roy (IIT M
From playlist Waves, Instabilities and Mixing in Rotating and Stratified Flows (ONLINE)

The second E-Lecture about PDE adverbials deals with the functional subdivision of this complex class. Using numerous examples, Prof. Handke discusses the central properties that keep adjuncts and subjuncts, on the one hand, and disjuncts and conjuncts, on the other, apart.
From playlist VLC201 - The Structure of English

Ses 18: Capital Budgeting II & Efficient Markets I
MIT 15.401 Finance Theory I, Fall 2008 View the complete course: http://ocw.mit.edu/15-401F08 Instructor: Andrew Lo License: Creative Commons BY-NC-SA More information at http://ocw.mit.edu/terms More courses at http://ocw.mit.edu
From playlist MIT 15.401 Finance Theory I, Fall 2008

Evaluation 5: relevance judgments
Relevance judgments indicate which documents are relevant to the information need of a user. They are constructed by trained annotators inspecting a subset of documents (typically pooled across a large number of different retrieval algorithms).
From playlist IR13 Evaluating Search Engines

The SL (2, R) action on spaces of differentials (Lecture 02) by Jayadev Athreya
DISCUSSION MEETING SURFACE GROUP REPRESENTATIONS AND PROJECTIVE STRUCTURES ORGANIZERS: Krishnendu Gongopadhyay, Subhojoy Gupta, Francois Labourie, Mahan Mj and Pranab Sardar DATE: 10 December 2018 to 21 December 2018 VENUE: Ramanujan Lecture Hall, ICTS Bangalore The study of spaces o
From playlist Surface group representations and Projective Structures (2018)