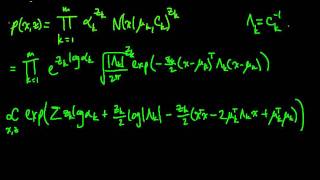Systems of probability distributions
Mixture distribution
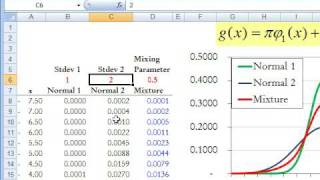
In probability and statistics, a mixture distribution is the probability distribution of a random variable that is derived from a collection of other random variables as follows: first, a random variable is selected by chance from the collection according to given probabilities of selection, and then the value of the selected random variable is realized. The underlying random variables may be random real numbers, or they may be random vectors (each having the same dimension), in which case the mixture distribution is a multivariate distribution. In cases where each of the underlying random variables is continuous, the outcome variable will also be continuous and its probability density function is sometimes referred to as a mixture density. The cumulative distribution function (and the probability density function if it exists) can be expressed as a convex combination (i.e. a weighted sum, with non-negative weights that sum to 1) of other distribution functions and density functions. The individual distributions that are combined to form the mixture distribution are called the mixture components, and the probabilities (or weights) associated with each component are called the mixture weights. The number of components in a mixture distribution is often restricted to being finite, although in some cases the components may be countably infinite in number. More general cases (i.e. an uncountable set of component distributions), as well as the countable case, are treated under the title of compound distributions. A distinction needs to be made between a random variable whose distribution function or density is the sum of a set of components (i.e. a mixture distribution) and a random variable whose value is the sum of the values of two or more underlying random variables, in which case the distribution is given by the convolution operator. As an example, the sum of two jointly normally distributed random variables, each with different means, will still have a normal distribution. On the other hand, a mixture density created as a mixture of two normal distributions with different means will have two peaks provided that the two means are far enough apart, showing that this distribution is radically different from a normal distribution. Mixture distributions arise in many contexts in the literature and arise naturally where a statistical population contains two or more subpopulations. They are also sometimes used as a means of representing non-normal distributions. Data analysis concerning statistical models involving mixture distributions is discussed under the title of mixture models, while the present article concentrates on simple probabilistic and statistical properties of mixture distributions and how these relate to properties of the underlying distributions. (Wikipedia).