
Introduction to the Gradient Theory and Formulas
Introduction to the Gradient Theory and Formulas If you enjoyed this video please consider liking, sharing, and subscribing. You can also help support my channel by becoming a member https://www.youtube.com/channel/UCr7lmzIk63PZnBw3bezl-Mg/join Thank you:)
From playlist Calculus 3
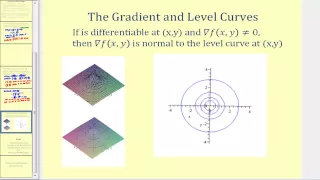
This video explains what information the gradient provides about a given function. http://mathispower4u.wordpress.com/
From playlist Functions of Several Variables - Calculus

11_3_1 The Gradient of a Multivariable Function
Using the partial derivatives of a multivariable function to construct its gradient vector.
From playlist Advanced Calculus / Multivariable Calculus
Find the Gradient Vector Field of f(x,y)=x^3y^5
This video explains how to find the gradient of a function. It also explains what the gradient tells us about the function. The gradient is also shown graphically. http://mathispower4u.com
From playlist The Chain Rule and Directional Derivatives, and the Gradient of Functions of Two Variables

Find the Gradient Vector Field of f(x,y)=ln(2x+5y)
This video explains how to find the gradient of a function. It also explains what the gradient tells us about the function. The gradient is also shown graphically. http://mathispower4u.com
From playlist The Chain Rule and Directional Derivatives, and the Gradient of Functions of Two Variables

Jorge Nocedal: "Tutorial on Optimization Methods for Machine Learning, Pt. 1"
Graduate Summer School 2012: Deep Learning, Feature Learning "Tutorial on Optimization Methods for Machine Learning, Pt. 1" Jorge Nocedal, Northwestern University Institute for Pure and Applied Mathematics, UCLA July 19, 2012 For more information: https://www.ipam.ucla.edu/programs/summ
From playlist GSS2012: Deep Learning, Feature Learning

Lecture 8.1 — A brief overview of Hessian-free optimization [Neural Networks for Machine Learning]
Lecture from the course Neural Networks for Machine Learning, as taught by Geoffrey Hinton (University of Toronto) on Coursera in 2012. Link to the course (login required): https://class.coursera.org/neuralnets-2012-001
From playlist [Coursera] Neural Networks for Machine Learning — Geoffrey Hinton

Approximating the Jacobian: Finite Difference Method for Systems of Nonlinear Equations
Generalized Finite Difference Method for Simultaneous Nonlinear Systems by approximating the Jacobian using the limit of partial derivatives with the forward finite difference. Example code on GitHub https://www.github.com/osveliz/numerical-veliz Chapters 0:00 Intro 0:13 Prerequisites 0:3
From playlist Solving Systems of Nonlinear Equations



11. Unconstrained Optimization; Newton-Raphson and Trust Region Methods
MIT 10.34 Numerical Methods Applied to Chemical Engineering, Fall 2015 View the complete course: http://ocw.mit.edu/10-34F15 Instructor: James Swan Students learned how to solve unconstrained optimization problems. In addition of the Newton-Raphson method, students also learned the steepe
From playlist MIT 10.34 Numerical Methods Applied to Chemical Engineering, Fall 2015

Optimization with inexact gradient and function by Serge Gratton
DISCUSSION MEETING : STATISTICAL PHYSICS OF MACHINE LEARNING ORGANIZERS : Chandan Dasgupta, Abhishek Dhar and Satya Majumdar DATE : 06 January 2020 to 10 January 2020 VENUE : Madhava Lecture Hall, ICTS Bangalore Machine learning techniques, especially “deep learning” using multilayer n
From playlist Statistical Physics of Machine Learning 2020


Lecture 8A : A brief overview of "Hessian Free" optimization
Neural Networks for Machine Learning by Geoffrey Hinton [Coursera 2013] Lecture 8A : A brief overview of "Hessian Free" optimization
From playlist Neural Networks for Machine Learning by Professor Geoffrey Hinton [Complete]


Inverse problems for Maxwell's equations (Lecture - 1) by Ting Zhou
DISCUSSION MEETING WORKSHOP ON INVERSE PROBLEMS AND RELATED TOPICS (ONLINE) ORGANIZERS: Rakesh (University of Delaware, USA) and Venkateswaran P Krishnan (TIFR-CAM, India) DATE: 25 October 2021 to 29 October 2021 VENUE: Online This week-long program will consist of several lectures by
From playlist Workshop on Inverse Problems and Related Topics (Online)

Data assimilation and machine learning by Serge Gratton
DISCUSSION MEETING : STATISTICAL PHYSICS OF MACHINE LEARNING ORGANIZERS : Chandan Dasgupta, Abhishek Dhar and Satya Majumdar DATE : 06 January 2020 to 10 January 2020 VENUE : Madhava Lecture Hall, ICTS Bangalore Machine learning techniques, especially “deep learning” using multilayer n
From playlist Statistical Physics of Machine Learning 2020

Lecture 8/16 : More recurrent neural networks
Neural Networks for Machine Learning by Geoffrey Hinton [Coursera 2013] 8A A brief overview of "Hessian-Free" optimization 8B Modeling character strings with multiplicative connections 8C Learning to predict the next character using HF 8D Echo state networks
From playlist Neural Networks for Machine Learning by Professor Geoffrey Hinton [Complete]

The gradient captures all the partial derivative information of a scalar-valued multivariable function.
From playlist Multivariable calculus

Graham Taylor: "Learning Representations of Sequences"
Graduate Summer School 2012: Deep Learning, Feature Learning "Learning Representations of Sequences" Graham Taylor, University of Guelph Institute for Pure and Applied Mathematics, UCLA July 13, 2012 For more information: https://www.ipam.ucla.edu/programs/summer-schools/graduate-summer
From playlist GSS2012: Deep Learning, Feature Learning