
Softmax Function Explained In Depth with 3D Visuals
The softmax function is often used in machine learning to transform the outputs of the last layer of your neural network (the logits) into probabilities. In this video, I explain how the softmax function works and provide some intuition for thinking about it in higher dimensions. In additi
From playlist Machine Learning

Derivative of Sigmoid and Softmax Explained Visually
The derivative of the sigmoid function can be understood intuitively by looking at how the denominator of the function transforms the numerator. The derivative of the softmax function, which can be thought of as an extension of the sigmoid function to multiple classes, works in a very simi
From playlist Machine Learning

Introduction to Classification Models
Ever wonder what classification models do? In this quick introduction, we talk about what classifications models are, as well as what they are used for in machine learning. In machine learning there are many different types of models, all with different types of outcomes. When it comes t
From playlist Introduction to Machine Learning
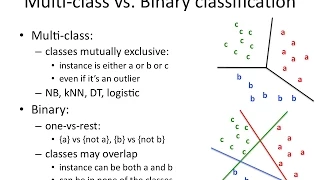

Why Do We Use the Sigmoid Function for Binary Classification?
This video explains why we use the sigmoid function in neural networks for machine learning, especially for binary classification. We consider both the practical side of making sure we get a consistent gradient from the standard categorical loss function, as well as making sure the equatio
From playlist Machine Learning
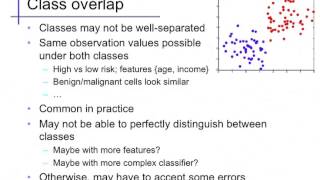
Linear classifiers (1): Basics
Definitions; decision boundary; separability; using nonlinear features
From playlist cs273a

Evgeni Dimitrov (Columbia) -- Towards universality for Gibbsian line ensembles
Gibbsian line ensembles are natural objects that arise in statistical mechanics models of random tilings, directed polymers, random plane partitions and avoiding random walks. In this talk I will discuss a general framework for establishing universal KPZ scaling limits for sequences of Gib
From playlist Columbia Probability Seminar
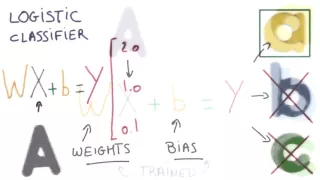
Training Your Logistic Classifier
This video is part of the Udacity course "Deep Learning". Watch the full course at https://www.udacity.com/course/ud730
From playlist Deep Learning | Udacity

The Softmax : Data Science Basics
All about the SOFTMAX function in machine learning!
From playlist Data Science Basics

An Introduction to Classification
Get a Free Trial: https://goo.gl/C2Y9A5 Get Pricing Info: https://goo.gl/kDvGHt Ready to Buy: https://goo.gl/vsIeA5 Develop predictive models for classifying data. For more videos, visit http://www.mathworks.com/products/statistics/examples.html
From playlist Math, Statistics, and Optimization

Sparse Graph Limits 1: Left and Right convergence - Jennifer Chayes
Conference on Graphs and Analysis Jennifer Chayes June 6, 2012 More videos on http://video.ias.edu
From playlist Mathematics

Stanford CS224N NLP with Deep Learning | Winter 2021 | Lecture 2 - Neural Classifiers
For more information about Stanford's Artificial Intelligence professional and graduate programs visit: https://stanford.io/2ZB72nu Lecture 2: Word Vectors, Word Senses, and Neural Network Classifiers 1. Course organization (2 mins) 2. Finish looking at word vectors and word2vec (13 mins)
From playlist Stanford CS224N: Natural Language Processing with Deep Learning | Winter 2021

Dynamics, Entropy Production & Defects in Active Matter (Lecture 3) by Sriram Ramaswamy
PROGRAM ENTROPY, INFORMATION AND ORDER IN SOFT MATTER ORGANIZERS: Bulbul Chakraborty, Pinaki Chaudhuri, Chandan Dasgupta, Marjolein Dijkstra, Smarajit Karmakar, Vijaykumar Krishnamurthy, Jorge Kurchan, Madan Rao, Srikanth Sastry and Francesco Sciortino DATE: 27 August 2018 to 02 Novemb
From playlist Entropy, Information and Order in Soft Matter

Tracy-Widom at each edge of real covariance and MANOVA estimators by Zhou Fan
PROGRAM :UNIVERSALITY IN RANDOM STRUCTURES: INTERFACES, MATRICES, SANDPILES ORGANIZERS :Arvind Ayyer, Riddhipratim Basu and Manjunath Krishnapur DATE & TIME :14 January 2019 to 08 February 2019 VENUE :Madhava Lecture Hall, ICTS, Bangalore The primary focus of this program will be on the
From playlist Universality in random structures: Interfaces, Matrices, Sandpiles - 2019

The structure behind the architecture - Lecture 1 by Olivier Hamant
ORGANIZERS : Vidyanand Nanjundiah and Olivier Rivoire DATE & TIME : 16 April 2018 to 26 April 2018 VENUE : Ramanujan Lecture Hall, ICTS Bangalore This program is aimed at Master's- and PhD-level students who wish to be exposed to interesting problems in biology that lie at the biology-
From playlist Living Matter 2018

Carolin Kreisbeck: Polycrystals and composites in single-slip crystal plasticity: the interplay...
CONFERENCE Recorded during the meeting " Beyond Elasticity: Advances and Research Challenges " the May 16, 2022 by the Centre International de Rencontres Mathématiques (Marseille, France) Filmmaker: Guillaume Hennenfent Find this video and other talks given by worldwide mathematician
From playlist Analysis and its Applications

Ensemble techniques leverage many weak learners to create a strong learner! This video describes the basic principle, variance/bias tradeoff, homogeneous/heterogenous ensembles, bagging vs boosting vs stacking and some detailed walkthroughs of decision trees, random forests, adaboost, grad
From playlist Materials Informatics

[Classic] Word2Vec: Distributed Representations of Words and Phrases and their Compositionality
#ai #research #word2vec Word vectors have been one of the most influential techniques in modern NLP to date. This paper describes Word2Vec, which the most popular technique to obtain word vectors. The paper introduces the negative sampling technique as an approximation to noise contrastiv
From playlist Papers Explained
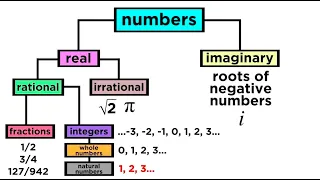
What are the Types of Numbers? Real vs. Imaginary, Rational vs. Irrational
We've mentioned in passing some different ways to classify numbers, like rational, irrational, real, imaginary, integers, fractions, and more. If this is confusing, then take a look at this handy-dandy guide to the taxonomy of numbers! It turns out we can use a hierarchical scheme just lik
From playlist Algebra 1 & 2
