
A #database #index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and storage space to maintain the index data structure. Indexes are used to quickly locate data without having to search every row in a database
From playlist Database

Indexing 1: what makes google fast
Every search engine makes use of a data structure called an "inverted index", which is similar to an index we find at the end of a book: for any keyword we store a list of pages where this word can be found. An index provides sub-linear access time to the matching pages.
From playlist IR7 Inverted Indexing

Web crawling 1: sources of data
A search engine typically acquires documents in one of three ways: (1) by monitoring a file system in desktop / enterprise search, (2) by subscribing to push and pull feeds (blogs, twitter, RSS) and (3) by crawling the web.
From playlist IR10 Crawling the Web

An intro to the core protocols of the Internet, including IPv4, TCP, UDP, and HTTP. Part of a larger series teaching programming. See codeschool.org
From playlist The Internet

O'Reilly Webcast: Adding Value with Metadata: Open up the Index
In this webcast presentation we'll explore new paths for reusing content metadata for discovery and recommendations. Indexes are one of the most detailed metadata sets available for your content, and can be used to search, recommend, explore, and create buyers for your publications. We'll
From playlist O'Reilly Webcasts 2

Web crawling 6: keeping index fresh
As a search engine, you want to keep your index as "fresh" as possible, i.e. the entries in your index should have the same content as the pages on the web. We can estimate the "age" of a webpage by assuming that page updates follow a Poisson process and estimating the rate of updates from
From playlist IR10 Crawling the Web

Web crawling 2: blogs, tweets, news feeds
In the publish/subscribe platform, the content provider releases a document into a feed and never makes changes to it. The search engine monitors the feed, and indexes all documents in it. We describe two types of feeds: pull feeds (blogs, twitter, RSS) and push feeds (commercial news aggr
From playlist IR10 Crawling the Web

SQL Index |¦| Indexes in SQL |¦| Database Index
Indexes in SQL are used to speed up SQL queries. A database index works much like an index in a book. For example, if you have a database table with a list of people, a common query would be to lookup someone by name. Creating an index means the database will not have to scan the entire
From playlist Introduction to SQL (Computer Science)

In this video, you’ll learn about HTML and how it is used to code webpages. We hope you enjoy! To learn more, check out our Basic HTML tutorial here: https://edu.gcfglobal.org/en/basic-html/ #whatishtml #htmlcode #learnhtml
From playlist HTML

Detecting semantic shift in large corpora by exploiting temporal random indexing
During the last decade, the surge in available data spanning different epochs has inspired a new analysis of cultural, social, and linguistic phenomena from a temporal perspective. In this talk, I will describe Temporal Random Indexing (TRI) a method that enables the analysis of the time e
From playlist Turing Seminars

How To Create A Back-End User Authentication Server | Session 22 | #unity3D | #gamedev
Don’t forget to subscribe! This project series will guide you on how to code a user authentication server, use Unity3D web requests, set up a user database, and learn how to communicate to the server, and of course, not forgetting about the security of the user data. You will be guided t
From playlist Create A Backend User Authentication Server For Unity3D

Google Search Console Tutorial | How To Use Google Search Console? | Search Console | Simplilearn
This video by Simplilearn on the Google Search Console will give you a detailed introduction to Google Search Console and help you learn the technical fundamentals about the Google search Console. This GSC tutorial by Simplilearn will guide you about how to set up the google search console
From playlist SEO Course [2022 Updated]
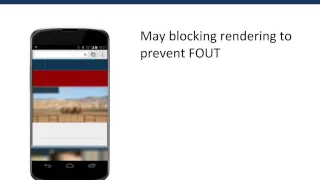
What Makes Mobile Websites Tick, How Do We Make Them Faster
Originally aired June 12, 2014. The HTTP Archive allows us to research trends in mobile website development. In this webcast, we'll look to discover the fastest designs for mobile performance in use on the web today and answer: How are websites changing over time? How do these ch
From playlist O'Reilly Webcasts 3

Elementary Introduction To Wolfram Language - Machine Learning | Session 28 | #datascience
Don’t forget to subscribe! This project series is an elementary introduction to the wolfram language. Developed by Wolfram Research, it is a multi-paradigm programming language. It is the language of the mathematical symbolic computation program Mathematica. It is scalable for programs
From playlist Elementary Introduction To Wolfram Language

How To Create A Web Crawler In Python | Session 02 | #python | #programming
Don’t forget to subscribe! This project is about creating a web crawler in Python. This series will cover the widely used Python framework - Scrapy. You will learn how to use this great tool to create your own web scrapers/crawlers. We are going to create a couple of different spiders in
From playlist Create A Web Crawler Using Python

How To Do Footprinting & Reconnaissance As A CEH | Session 07 | #cybersecurity
Don’t forget to subscribe! In this cybersecurity tutorial, you will learn how to do footprinting and reconnaissance as a CEH. Computer and network security is a complex subject and an ever-moving target. we must stay aware and on top of it so that our information is protected from var
From playlist Footprinting & Reconnaissance As A CEH

How To Create A Security Token In Ethereum | Session 07 | #blockchain
Don’t forget to subscribe! In this project series, you will learn to create a security token in Ethereum. This tutorial will cover all the details that are necessary to build an Ethereum based security token. You will be guided through all the steps of creating and deploying your securi
From playlist Create A Security Token In Ethereum

New-Age Search Through Solr | Edureka
Watch Sample Recording : http://www.edureka.co/apache-solr?utm_source=youtube&utm_medium=webinar&utm_campaign=solr-18-6-15 Apache Solr based on the Lucene Library, is an open-source enterprise Grade search engine and platform used to provide fa
From playlist Webinars by Edureka!


How To Create Billing System In C# and ASP .NET | Session 02 | #programming
Don’t forget to subscribe! This project series will guide on how to create a billing system in C and ASP.NET This tutorial will cover all the details (resources, tools, languages etc) that are necessary to create a complete and operational web-based billing system in C# and ASP.NET. You
From playlist Create Billing System In C# and ASP .NET