
👉 Learn about graphing linear equations. A linear equation is an equation whose highest exponent on its variable(s) is 1. i.e. linear equations has no exponents on their variables. The graph of a linear equation is a straight line. To graph a linear equation, we identify two values (x-valu
From playlist ⚡️Graph Linear Equations | Learn About

👉 Learn about graphing linear equations. A linear equation is an equation whose highest exponent on its variable(s) is 1. i.e. linear equations has no exponents on their variables. The graph of a linear equation is a straight line. To graph a linear equation, we identify two values (x-valu
From playlist ⚡️Graph Linear Equations | Learn About

Vector form of multivariable quadratic approximation
This is the more general form of a quadratic approximation for a scalar-valued multivariable function. It is analogous to a quadratic Taylor polynomial in the single-variable world.
From playlist Multivariable calculus
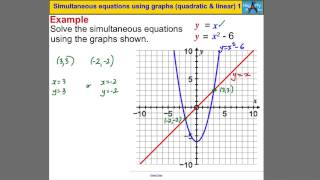
Simultaneous equations using graphs (quadratic & linear) 1
Powered by https://www.numerise.com/ Simultaneous equations using graphs (quadratic & linear) 1
From playlist Quadratic sequences & graphs

Jorge Nocedal: "Tutorial on Optimization Methods for Machine Learning, Pt. 3"
Graduate Summer School 2012: Deep Learning, Feature Learning "Tutorial on Optimization Methods for Machine Learning, Pt. 3" Jorge Nocedal, Northwestern University Institute for Pure and Applied Mathematics, UCLA July 18, 2012 For more information: https://www.ipam.ucla.edu/programs/summ
From playlist GSS2012: Deep Learning, Feature Learning

Quadratic Simultaneous Equations
"Solve simultaneous equations where one is quadratic, one is linear."
From playlist Algebra: Simultaneous Equations

Lecture 11 | Convex Optimization II (Stanford)
Lecture by Professor Stephen Boyd for Convex Optimization II (EE 364B) in the Stanford Electrical Engineering department. Professor Boyd lectures on Sequential Convex Programming. This course introduces topics such as subgradient, cutting-plane, and ellipsoid methods. Decentralized conv
From playlist Lecture Collection | Convex Optimization
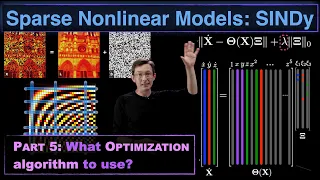
Sparse Nonlinear Dynamics Models with SINDy, Part 5: The Optimization Algorithms
This video discusses the various machine learning optimization schemes that may be used for the Sparse Identification of Nonlinear Dynamics (SINDy) algorithm. We discuss the LASSO sparse regression, sequential thresholded least squares (STLS), and the sparse relaxed regularized regression
From playlist Data-Driven Dynamical Systems with Machine Learning

Lecture 8 | MIT 6.832 Underactuated Robotics, Spring 2009
Lecture 8: Dynamic programming (DP) and policy search Instructor: Russell Tedrake See the complete course at: http://ocw.mit.edu/6-832s09 License: Creative Commons BY-NC-SA More information at http://ocw.mit.edu/terms More courses at http://ocw.mit.edu
From playlist MIT 6.832 Underactuated Robotics, Spring 2009

👉 Learn about graphing linear equations. A linear equation is an equation whose highest exponent on its variable(s) is 1. i.e. linear equations has no exponents on their variables. The graph of a linear equation is a straight line. To graph a linear equation, we identify two values (x-valu
From playlist ⚡️Graph Linear Equations | Learn About
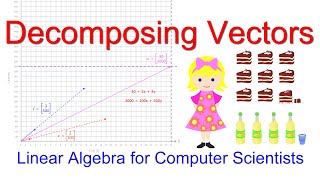
Linear Algebra for Computer Scientists. 9. Decomposing Vectors
This computer science video is one of a series on linear algebra for computer scientists. In this video you will learn how to express a given vector as a linear combination of a set of given basis vectors. In other words, you will learn how to determine the coefficients that were used to
From playlist Linear Algebra for Computer Scientists

Powered by https://www.numerise.com/ Formulating a linear programming problem
From playlist Linear Programming - Decision Maths 1

Overview of Approaches to Data Assimilation - Christopher Jones
PROGRAM: Data Assimilation Research Program Venue: Centre for Applicable Mathematics-TIFR and Indian Institute of Science Dates: 04 - 23 July, 2011 DESCRIPTION: Data assimilation (DA) is a powerful and versatile method for combining observational data of a system with its dynamical mod
From playlist Data Assimilation Research Program

what is linear and non linear in machine learning, deep learning
what is linear and non linear in machine learning and deep learning? you will have clear understanding after watching this video. all machine learning youtube videos from me, https://www.youtube.com/playlist?list=PLVNY1HnUlO26x597OgAN8TCgGTiE-38D6
From playlist Machine Learning

Replication or Exploration? Sequential Design for Stochastic Simulation Experiments
The Data Science Institute (DSI) hosted a virtual seminar by Robert Gramacy from Virginia Tech on March 15, 2021. Read more about the DSI seminar series at https://data-science.llnl.gov/latest/seminar-series. We investigate the merits of replication and provide methods that search for opti
From playlist DSI Virtual Seminar Series

10. Understanding Program Efficiency, Part 1
MIT 6.0001 Introduction to Computer Science and Programming in Python, Fall 2016 View the complete course: http://ocw.mit.edu/6-0001F16 Instructor: Prof. Eric Grimson In this lecture, Prof. Grimson introduces algorithmic complexity, a rough measure of the efficiency of a program. He then
From playlist 6.0001 Introduction to Computer Science and Programming in Python. Fall 2016

Lecture 17 | Convex Optimization II (Stanford)
Lecture by Professor Stephen Boyd for Convex Optimization II (EE 364B) in the Stanford Electrical Engineering department. Professor Boyd lectures on Stochastic Model Predictive Control, he then begins discussing Branch-and-bound methods. This course introduces topics such as subgradient
From playlist Lecture Collection | Convex Optimization
Statistical Rethinking 2022 Lecture 08 - Markov chain Monte Carlo
Slides and other course materials: https://github.com/rmcelreath/stat_rethinking_2022 Music: Intro: https://www.youtube.com/watch?v=E06X1NXRdR4 Skate1 vid: https://www.youtube.com/watch?v=GCr0EO41t8g Skate1 music: https://www.youtube.com/watch?v=o3WvAhOAoCg Skate2 vid: https://www.youtube
From playlist Statistical Rethinking 2022

What is the slope of a linear equation
👉 Learn about graphing linear equations. A linear equation is an equation whose highest exponent on its variable(s) is 1. i.e. linear equations has no exponents on their variables. The graph of a linear equation is a straight line. To graph a linear equation, we identify two values (x-valu
From playlist ⚡️Graph Linear Equations | Learn About

Data Assimilation in Global NWP... - Bonavita - Workshop 2 - CEB T3 2019
Bonavita (ECMWF, UK) / 12.11.2019 Data Assimilation in Global NWP: A case study in Big Data and Uncertainty Quantification ---------------------------------- Vous pouvez nous rejoindre sur les réseaux sociaux pour suivre nos actualités. Facebook : https://www.facebook.com/Institut
From playlist 2019 - T3 - The Mathematics of Climate and the Environment