
B25 Example problem solving for a Bernoulli equation
See how to solve a Bernoulli equation.
From playlist Differential Equations

Illustrates the solution of a Bernoulli first-order differential equation. Free books: http://bookboon.com/en/differential-equations-with-youtube-examples-ebook http://www.math.ust.hk/~machas/differential-equations.pdf
From playlist Differential Equations with YouTube Examples
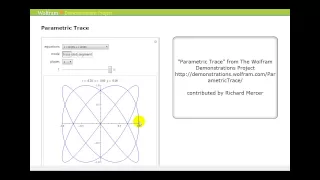
Introduction to Parametric Equations
This video defines a parametric equations and shows how to graph a parametric equation by hand. http://mathispower4u.yolasite.com/
From playlist Parametric Equations

Illustrates the solution of a Riccati first-order differential equation. Free books: http://bookboon.com/en/differential-equations-with-youtube-examples-ebook http://www.math.ust.hk/~machas/differential-equations.pdf
From playlist Differential Equations with YouTube Examples

The Role of the Transpose in Free Probability - J.Mingo - Workshop 2 - CEB T3 2017
James Mingo / 26.10.17 The Role of the Transpose in Free Probability: the partial transpose of R-cyclic operators Like tensor independence, free independence gives us rules for doing calculations. With random matrix models, we usually need tensor independence of the entries and some kin
From playlist 2017 - T3 - Analysis in Quantum Information Theory - CEB Trimester

Iain Johnstone: Eigenvalues and variance components
Abstract: Motivated by questions from quantitative genetics, we consider high dimensional versions of some common variance component models. We focus on quadratic estimators of 'genetic covariance' and study the behavior of both the bulk of the estimated eigenvalues and the largest estimat
From playlist Probability and Statistics

B24 Introduction to the Bernoulli Equation
The Bernoulli equation follows from a linear equation in standard form.
From playlist Differential Equations
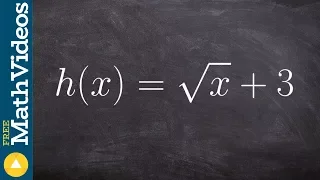
How to determine if an equation is a linear relation
👉 Learn how to determine if an equation is a linear equation. A linear equation is an equation whose highest exponent on its variable(s) is 1. The variables do not have negative or fractional, or exponents other than one. Variables must not be in the denominator of any rational term and c
From playlist Write Linear Equations

Sandrine Péché: Eigenvalue distribution for non linear models of random matrices
The talk concerned with the asymptotic empirical eigenvalue distribution of a non linear random matrix ensemble. More precisely we consider $M= \frac{1}{m} YY^*$ with $Y=f(WX)$ where W and X are random rectangular matrices with i.i.d. centered entries. The function f is applied pointwise
From playlist Probability and Statistics

Tracy-Widom at each edge of real covariance and MANOVA estimators by Zhou Fan
PROGRAM :UNIVERSALITY IN RANDOM STRUCTURES: INTERFACES, MATRICES, SANDPILES ORGANIZERS :Arvind Ayyer, Riddhipratim Basu and Manjunath Krishnapur DATE & TIME :14 January 2019 to 08 February 2019 VENUE :Madhava Lecture Hall, ICTS, Bangalore The primary focus of this program will be on the
From playlist Universality in random structures: Interfaces, Matrices, Sandpiles - 2019

Solve a Bernoulli Differential Equation Initial Value Problem
This video provides an example of how to solve an Bernoulli Differential Equations Initial Value Problem. The solution is verified graphically. Library: http://mathispower4u.com
From playlist Bernoulli Differential Equations

Michael Mahoney: "Why Deep Learning Works: Implicit Self-Regularization in Deep Neural Networks"
Machine Learning for Physics and the Physics of Learning 2019 Workshop II: Interpretable Learning in Physical Sciences "Why Deep Learning Works: Implicit Self-Regularization in Deep Neural Networks" Michael Mahoney, University of California, Berkeley (UC Berkeley) Abstract: Physics has a
From playlist Machine Learning for Physics and the Physics of Learning 2019
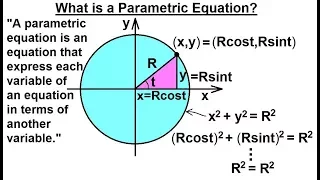
Calculus 2: Parametric Equations (1 of 20) What is a Parametric Equation?
Visit http://ilectureonline.com for more math and science lectures! In this video I will explain what is a parametric equation. A parametric equation is an equation that expresses each variable of an equation in terms of another variable. Next video in the series can be seen at: https://
From playlist CALCULUS 2 CH 17 PARAMETRIC EQUATIONS

Igor Marchenko from HP Vertica interviewed at Strata Rx 2013
Igor Marchenko, HP Vertica
From playlist Strata Rx Conference 2013

Summary for graph an equation in Standard form
👉 Learn about graphing linear equations. A linear equation is an equation whose highest exponent on its variable(s) is 1. i.e. linear equations has no exponents on their variables. The graph of a linear equation is a straight line. To graph a linear equation, we identify two values (x-valu
From playlist ⚡️Graph Linear Equations | Learn About

For more training resources, visit: http://www.wolfram.com/training/ See how easy it is to use the Wolfram Language to solve real-world statistics and probability problems with quantity data, enhanced time series support, and over 150 distributions, including random matrices. Notebook li
From playlist New in the Wolfram Language and Mathematica Version 11

Eigenvalue bounds on sums of random matrices - Adam Marcus
Members’ Seminar Topic:Eigenvalue bounds on sums of random matrices Speaker: Adam Marcus Affilation: Princeton University Date: November 14, 2016 For more videos, visit http://video.ias.edu
From playlist Mathematics

Catherine Sulem: Soliton Resolution for Derivative NLS equation
Abstract: We consider the Derivative Nonlinear Schrödinger equation for general initial conditions in weighted Sobolev spaces that can support bright solitons (but exclude spectral singularities). We prove global wellposedness and give a full description of the long-time behavior of the s
From playlist Women at CIRM
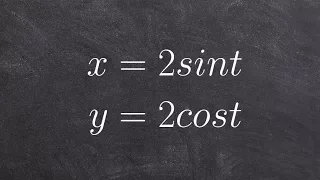
Learn how to eliminate the parameter with trig functions
Learn how to eliminate the parameter in a parametric equation. A parametric equation is a set of equations that express a set of quantities as explicit functions of a number of independent variables, known as parameters. Eliminating the parameter allows us to write parametric equation in r
From playlist Parametric Equations

Nexus Trimester - Gregory Valiant (Stanford) 2/2
When your big data seems too small: accurate inferences beyond the empirical distribution 2/2 Gregory Valiant (Stanford) March 14, 2016 Abstract: We discuss three problems related to the general challenge of making accurate inferences about a complex distribution, in the regime in which
From playlist 2016-T1 - Nexus of Information and Computation Theory - CEB Trimester