
Methods for Constrained Local and Global Optimization
Constrained optimization algorithms have been under active development in recent years, with numerous open-source and commercial library solvers emerging for convex, nonconvex, local and global optimization. This talk will cover the Wolfram Language numerical optimization functions for con
From playlist Wolfram Technology Conference 2021

Worldwide Calculus: Optimization
Lecture on 'Optimization' from 'Worldwide Multivariable Calculus'. For more lecture videos and $10 digital textbooks, visit www.centerofmath.org.
From playlist Multivariable Derivatives

13_1 An Introduction to Optimization in Multivariable Functions
Optimization in multivariable functions: the calculation of critical points and identifying them as local or global extrema (minima or maxima).
From playlist Advanced Calculus / Multivariable Calculus

Worldwide Calculus: Optimization
Lecture on Optimization from 'Worldwide Differential Calculus' and 'Worldwide AP Calculus'. For more lecture videos and $10 digital textbooks, visit www.centerofmath.org.
From playlist Worldwide Single-Variable Calculus for AP®

A combinatorial approach to the determinant using permutations.
From playlist Linear Algebra

This talk will discuss the global optimization functionality in Wolfram Language. It builds upon the convex and convertible to convex optimization functionality developed previously and extends to functionality for solving nonlinear, nonconvex problems with real-valued and mixed-integer va
From playlist Wolfram Technology Conference 2022

Constrained optimization introduction
See a simple example of a constrained optimization problem and start getting a feel for how to think about it. This introduces the topic of Lagrange multipliers.
From playlist Multivariable calculus

Motion Planning Via Moment Optimization
Motion planning is a fundamental problem in robotics. In this talk we attack this problem with techniques from the fields of "Moment Optimization" and "Semidefinite Programming". Our method shows promise in handling obstacles that vary with time, and provides formal guarantees on the qual
From playlist Conference Talks

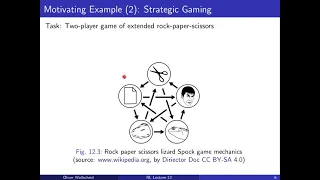
Lecture 12: Policy Gradient Methods
Twelth lecture video on the course "Reinforcement Learning" at Paderborn University during the summer term 2020. Source files are available here: https://github.com/upb-lea/reinforcement_learning_course_materials
From playlist Reinforcement Learning Course: Lectures (Summer 2020)

DeepMind x UCL | Deep Learning Lectures | 5/12 | Optimization for Machine Learning
Optimization methods are the engines underlying neural networks that enable them to learn from data. In this lecture, DeepMind Research Scientist James Martens covers the fundamentals of gradient-based optimization methods, and their application to training neural networks. Major topics in
From playlist Learning resources

Seminar In the Analysis and Methods of PDE (SIAM PDE): Andrea R. Nahmod
Title: Gibbs measures and propagation of randomness under the flow of nonlinear dispersive PDE Date: Thursday, May 5, 2022, 11:30 am EDT Speaker: Andrea R. Nahmod, University of Massachusetts Amherst The COVID-19 pandemic and consequent social distancing call for online venues of research
From playlist Seminar In the Analysis and Methods of PDE (SIAM PDE)

Lecture 13: Further Contemporary RL Algorithms
Thirteenth lecture video on the course "Reinforcement Learning" at Paderborn University during the summer term 2020. Source files are available here: https://github.com/upb-lea/reinforcement_learning_course_materials Intro: (0:00) Deep Deterministic Policy Gradient: (1:21) Twin Delayed D
From playlist Reinforcement Learning Course: Lectures (Summer 2020)

Alpár Mészáros: "Global well-posedness of master equations for deterministic displacement convex..."
High Dimensional Hamilton-Jacobi PDEs 2020 Workshop III: Mean Field Games and Applications "Global well-posedness of master equations for deterministic displacement convex potential mean field games" Alpár Mészáros - Durham University Abstract: In this talk we investigate the question of
From playlist High Dimensional Hamilton-Jacobi PDEs 2020

Nonconvex Stochastic Programs: Deterministic Constraints
Jong-Shi Pang University of Southern California, USA
From playlist Distinguished Visitors Lecture Series

Nexus Trimester - Arkadev Chattopadhyay (TIFR)
Topology matters in communication Arkadev Chattopadhyay February 11, 2016 Abstract: We study communication cost of computing functions when inputs are distributed among k processors, each of which is located at one vertex of a network/graph called a terminal. Every other node of the netwo
From playlist Nexus Trimester - 2016 - Distributed Computation and Communication Theme

From playlist CS294-112 Deep Reinforcement Learning Sp17

Lecture 16 | MIT 6.832 Underactuated Robotics, Spring 2009
Lecture 16: Introducing stochastic optimal control Instructor: Russell Tedrake See the complete course at: http://ocw.mit.edu/6-832s09 License: Creative Commons BY-NC-SA More information at http://ocw.mit.edu/terms More courses at http://ocw.mit.edu
From playlist MIT 6.832 Underactuated Robotics, Spring 2009

On the Convergence of Deep Learning with Differential Privacy
A Google TechTalk, presented by Zhiqi Bu, 2021/07/02 ABSTRACT: Differential Privacy for ML Series. In deep learning with differential privacy (DP), the neural network achieves the privacy usually at the cost of slower convergence (and thus lower performance) than its non-private counterpa
From playlist Differential Privacy for ML
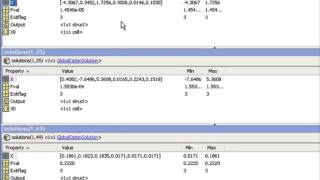
Using MultiStart for Optimization Problems
Get a Free Trial: https://goo.gl/C2Y9A5 Get Pricing Info: https://goo.gl/kDvGHt Ready to Buy: https://goo.gl/vsIeA5 Find the best-fit parameters for an exponential model. For more videos, visit http://www.mathworks.com/products/global-optimization/examples.html
From playlist Math, Statistics, and Optimization